System Architecture
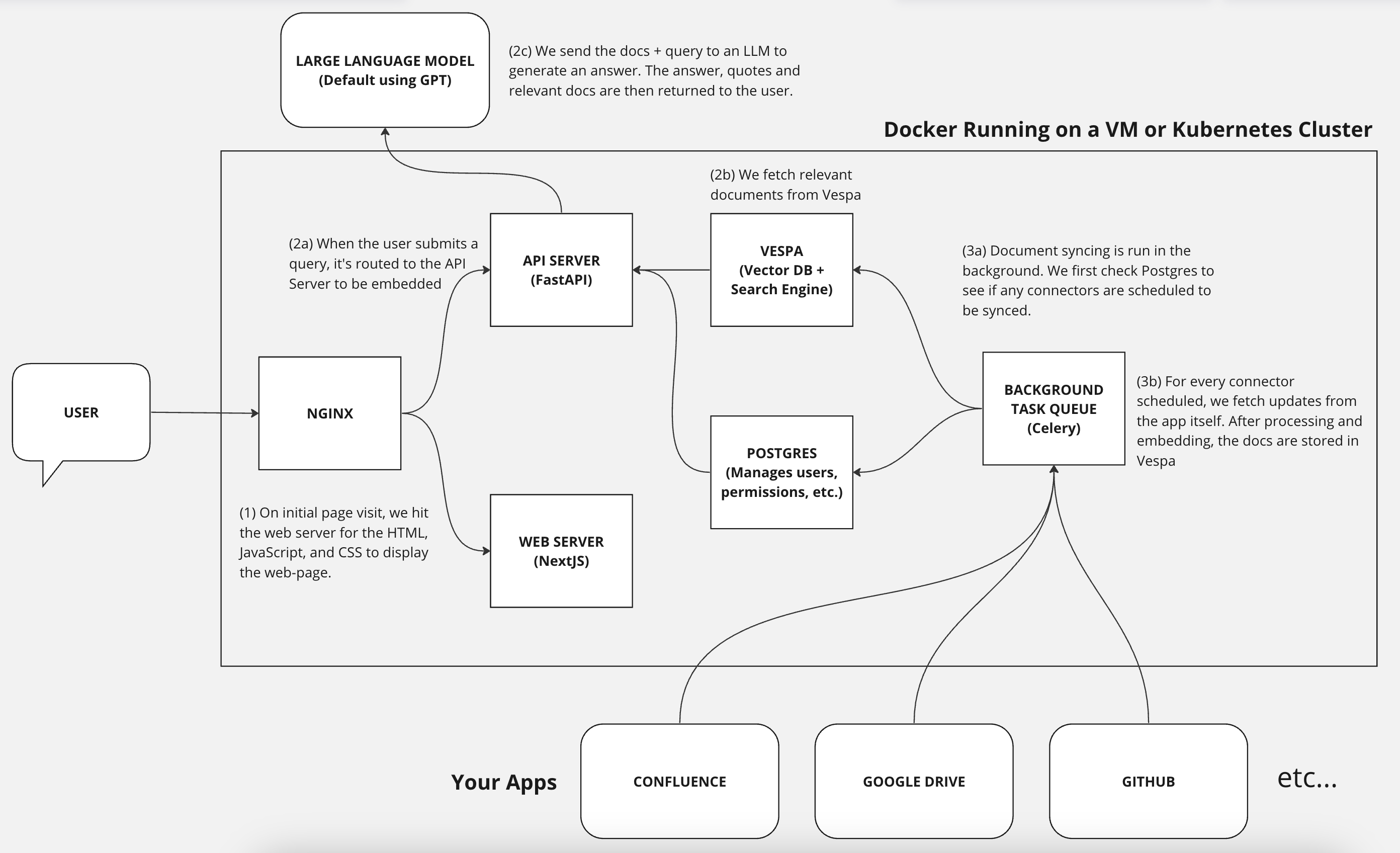
- Documents are pulled and processed via connectors.
- These are then stored in Vespa or Postgres, running in containers within your setup.
LLM Communication
The only time-sensitive data that leaves your system is when Hymalaia makes a request to a Large Language Model (LLM) for generating a response.- All communication with the LLM is encrypted.
- Data persistence policies depend on your LLM hosting provider.
🕵️ Hymalaia also includes minimal, anonymous telemetry to help improve the platform and monitor flaky connectors.
You can disable telemetry by setting the following environment variable:
Embedding Flow
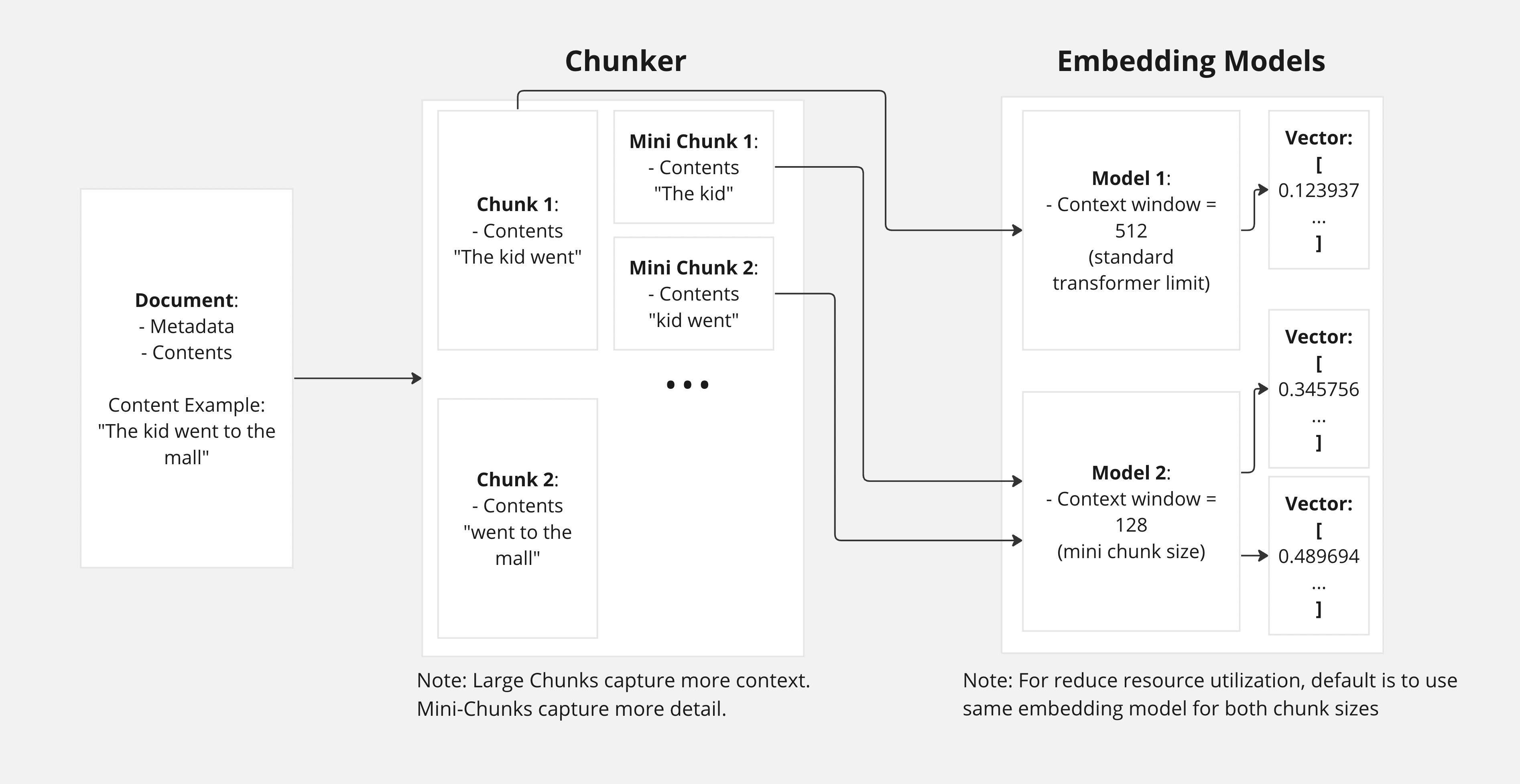
- Only relevant parts are passed to the LLM → less noise.
- Reduced cost: LLMs charge per token.
- Improved detail retention: Embedding vectors have limits on how much info they can store.
Mini-Chunks
Mini-chunks go one step further:- Create multiple embedding sizes.
- Improve retrieval of both high-level context and fine-grained details.
- Can be toggled using environment variables.
⚠️ Note: Mini-chunks may slow down indexing on low-performance hardware.
Embedding Model
Hymalaia uses a state-of-the-art biencoder, optimized for:- Running on CPUs
- Subsecond document retrieval
Query Flow
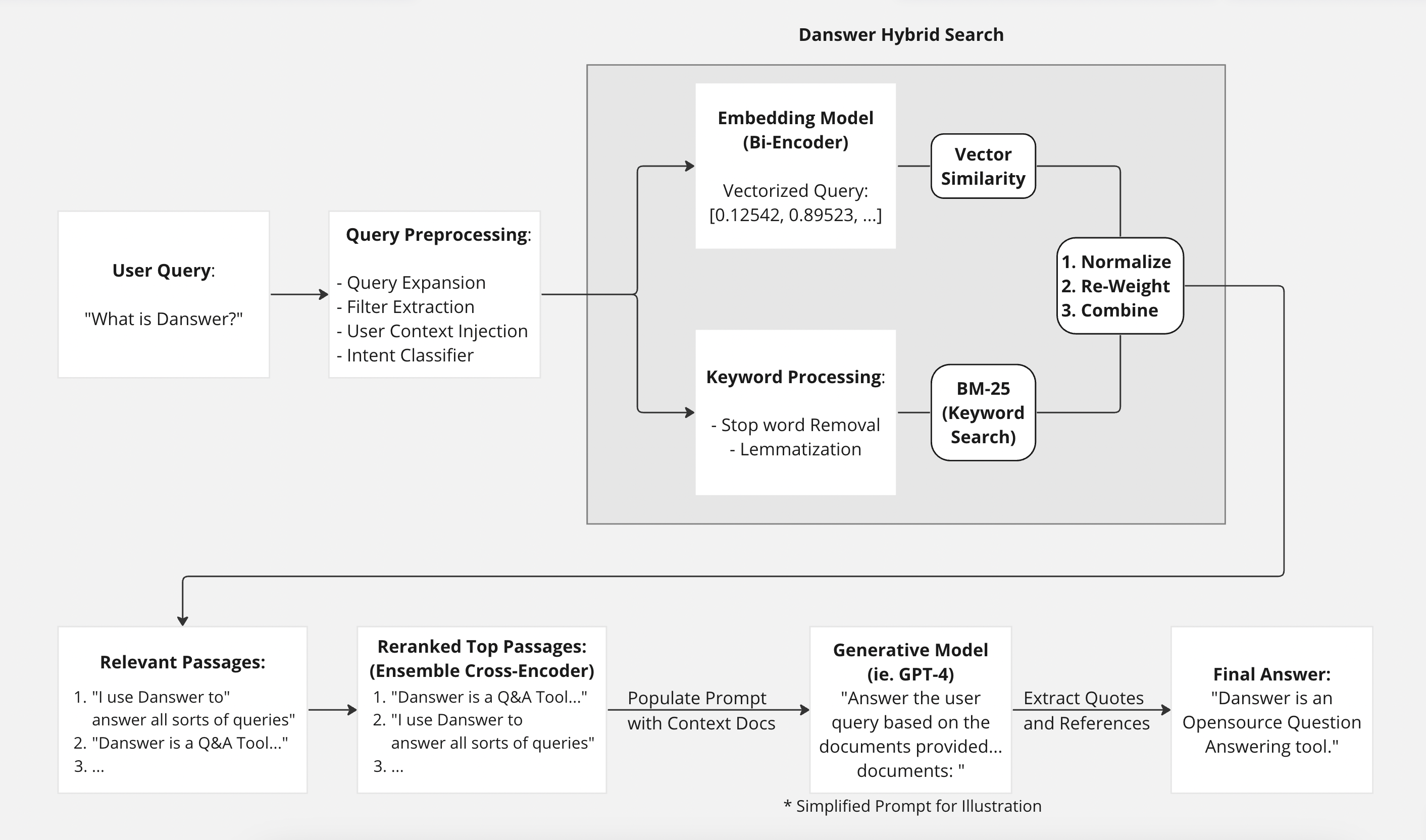
- Number of documents to retrieve
- Number of reranked documents
- Embedding and reranking models
- Chunk selection passed to the LLM
❓Have questions or ideas? Don’t hesitate to reach out to the maintainers.
Ready to dive deeper? Explore the Multilingual Setup or the Connector Guide to further customize your Hymalaia deployment.